Spark 3.0
Spark
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching and optimized query execution for fast queries against data of any size. Simply put, Spark is a fast and general engine for large-scale data processing.
The fast part means that it’s faster than previous approaches to work with Big Data like classical MapReduce. The secret for being faster is that Spark runs on memory (RAM), and that makes the processing much faster than on disk drives.
The general part means that it can be used for multiple things like running distributed SQL, creating data pipelines, ingesting data into a database, running Machine Learning algorithms, working with graphs or data streams, and much more.
Components of Spark
Spark as a whole consists of various libraries, APIs, databases, etc. The main components of Apache Spark are as follows:
Spark Core
Spare Core is the basic building block of Spark, which includes all components for job scheduling, performing various memory operations, fault tolerance, and more. Spark Core is also home to the API that consists of RDD. Moreover, Spark Core provides APIs for building and manipulating data in RDD.
Spark SQL
Apache Spark works with the unstructured data using its ‘go to’ tool, Spark SQL. Spark SQL allows querying data via SQL, as well as via Apache Hive’s form of SQL called Hive Query Language (HQL). It also supports data from various sources like parse tables, log files, JSON, etc. Spark SQL allows programmers to combine SQL queries with programmable changes or manipulations supported by RDD in Python, Java, Scala, and R.
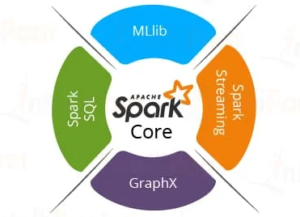
Spark Streaming
Spark Streaming processes live streams of data. Data generated by various sources is processed at the very instant by Spark Streaming. Examples of this data include log files, messages containing status updates posted by users, etc.
MLlib
Apache Spark comes up with a library containing common Machine Learning (ML) services called MLlib. It provides various types of ML algorithms including regression, clustering, and classification, which can perform various operations on data to get meaningful insights out of it.
GraphX
GraphX is Apache Spark’s library for enhancing graphs and enabling graph-parallel computation. Apache Spark includes a number of graph algorithms which help users in simplifying graph analytics.
Course Outline
Module 1: Introduction to Hadoop and it’s Ecosystem
The objective of this Apache Hadoop ecosystem components tutorial is to have an overview of what are the different components of Hadoop ecosystem that make Hadoop so powerful . We will also learn about Hadoop ecosystem components like HDFS and HDFS components, MapReduce, YARN, Hive, Apache Pig, Apache HBase and HBase components.
Module 2: What is Spark and it’s Architecture
This module introduces the on Spark, open-source projects from Apache Software Foundation which mainly used for Big Data Analytics. Here we will try to see the key difference between MapReduce and Spark is their approach toward data processing.
Hands-on : Local Installation of Spark with Python
Hand-on : Databricks Setup
Module 3: Python – A Quick Review (Optional)
In this module, you will get a quick review on Python Language. We will not going in depth but we will try to discuss some important components of Python Language.
Hands-on : Python Code Along
Hands-on : Python Review Exercise
Module 4: Spark DataFrame Basics
Data is a fundamental element in any machine learning workload, so in this module, we will learn how to create and manage datasets using Spark DataFrame. We will also try to get some knowledge on RDD,which is the fundamental Data Structure of Spark.
Hands-on : Working with DataFrame
Module 5: Introduction to Machine Learning with MLlib
The goal of this series is to help you get started with Apache Spark’s ML library. Together we will explore how to solve various interesting machine learning use-cases in a well structured way. By the end, you will be able to use Spark ML with high confidence and learn to implement an organized and easy to maintain workflow for your future projects.
Hands-on : Consultancy Project on Linear Regression
Hands-on : Consultancy Project on Logistic Regression
Module 6: Spark Structured Streaming
In a world where we generate data at an extremely fast rate, the correct analysis of the data and providing useful and meaningful results at the right time can provide helpful solutions for many domains dealing with data products. One of the amazing frameworks that can handle big data in real-time and perform different analysis, is Apache Spark. In this section, we are going to use spark streaming to process high-velocity data at scale.
Hands-on : Spark Structured Streaming Code Along
Code Along - Databricks Notebook
- Python Refresh Code Along
- Python Crash Course Exercise Solution: Click here
- Dataframe Operations: Click here
- DataFrame Exercise Solution: Click here
- Simple ETL Pipeline: Click here
- [ DataSet : Simple_ETL_Dataset]
- Linear Regression Code Along: Click here
- Logistic Regression Exercise Solution: Click here
- Spark Structured Streaming: Click here
Dataset