I will explain how you can get started and combine automated machine learning and model interpretability to accelerate AI, while still making sure that models are highly interpretable, minimizing model risk and making it easy for any enterprise to comply with regulations and best practices.
Model interpretability with Azure Machine Learning service
When it comes to predictive modeling, you have to make a trade-off: Do you just want to know what is predicted? For example, the probability that a customer will churn or how effective some drug will be for a patient. Or do you want to know why the prediction was made and possibly pay for the interpretability with a drop in predictive performance?
In some cases, you do not care why a decision was made, it is enough to know that the predictive performance on a test dataset was good. But in other cases, knowing the ‘why’ can help you learn more about the problem, the data and the reason why a model might fail.
In this post, you learn how to explain why your model made the predictions it did with the various interpretability packages of the Azure Machine Learning Python SDK.
Using the classes and methods in the SDK, you can get:
- Feature importance values for both raw and engineered features
- Interpretability on real-world datasets at scale, during training and inference.
- Interactive visualizations to aid you in the discovery of patterns in data and explanations at training time
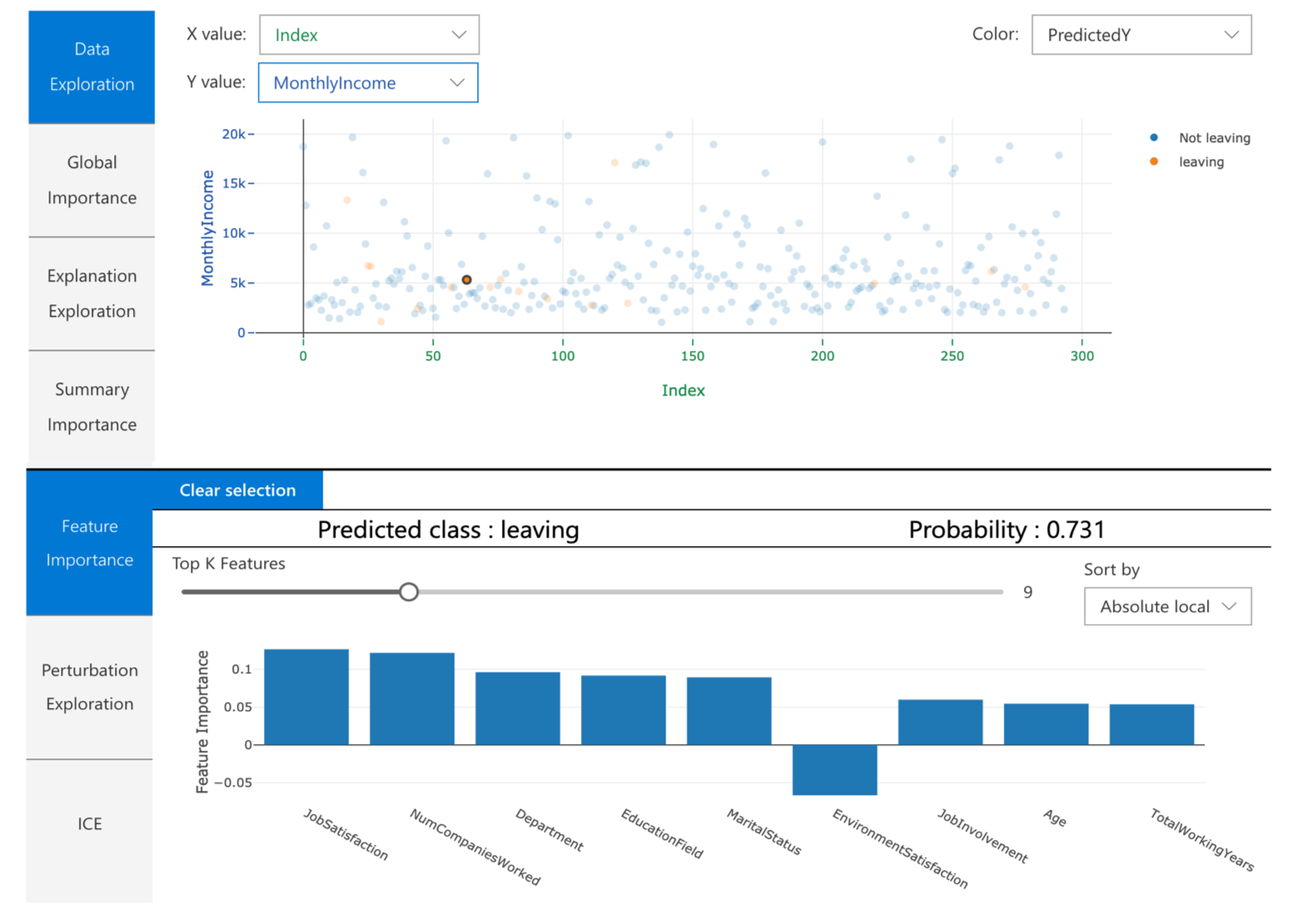
In machine learning, features are the data fields used to predict a target data point. For example, to predict credit risk, data fields for age, account size, and account age might be used. In this case, age, account size, and account age are features. Feature importance tells you how each data field affected the model’s predictions. For example, age may be heavily used in the prediction while account size and age don’t affect the prediction accuracy significantly. This process allows data scientists to explain resulting predictions, so that stakeholders have visibility into what data points are most important in the model.
Using these tools, you can explain machine learning models globally on all data, or locally on a specific data point using the state-of-art technologies in an easy-to-use and scalable fashion.
The interpretability classes are made available through multiple SDK packages. Learn how to install SDK packages for Azure Machine Learning.
azureml.explain.model, the main package, containing functionalities supported by Microsoft.azureml.contrib.explain.model, preview, and experimental functionalities that you can try.azureml.train.automl.automlexplainerpackage for interpreting automated machine learning models.
How to interpret your model
You can apply the interpretability classes and methods to understand the model’s global behavior or specific predictions. The former is called global explanation and the latter is called local explanation.
The methods can be also categorized based on whether the method is model agnostic or model specific. Some methods target certain type of models. For example, SHAP’s tree explainer only applies to tree-based models. Some methods treat the model as a black box, such as mimic explainer or SHAP’s kernel explainer. The explain package leverages these different approaches based on data sets, model types, and use cases.
The output is a set of information on how a given model makes its prediction, such as:
- Global/local relative feature importance
- Global/local feature and prediction relationship
Explainers
There are two sets of explainers: Direct Explainers and Meta Explainers in the SDK.
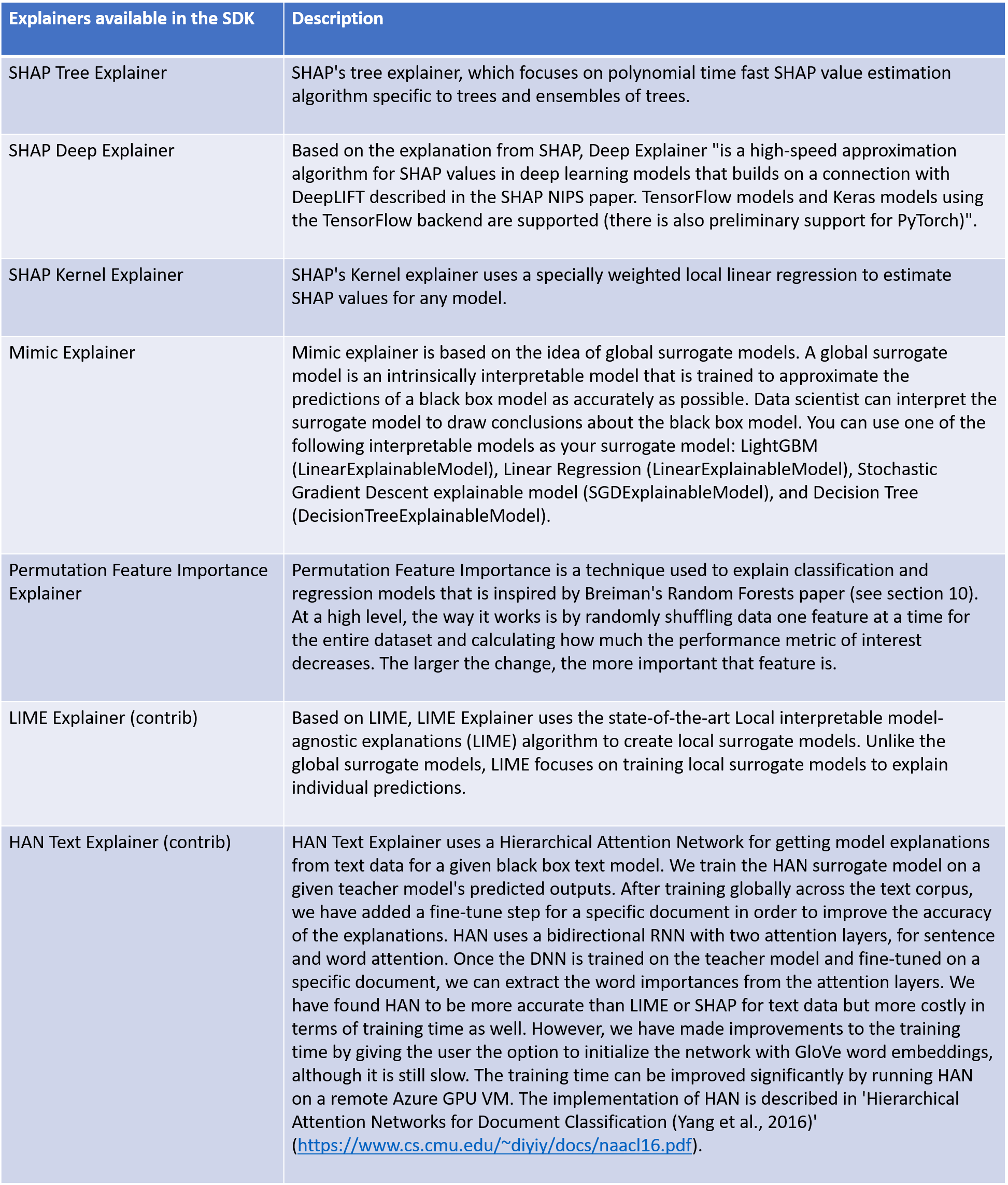
Direct explainers come from integrated libraries. The SDK wraps all the explainers so that they expose a common API and output format. If you are more comfortable directly using these explainers, you can directly invoke them instead of using the common API and output format. The following table lists the direct explainers available in the SDK:
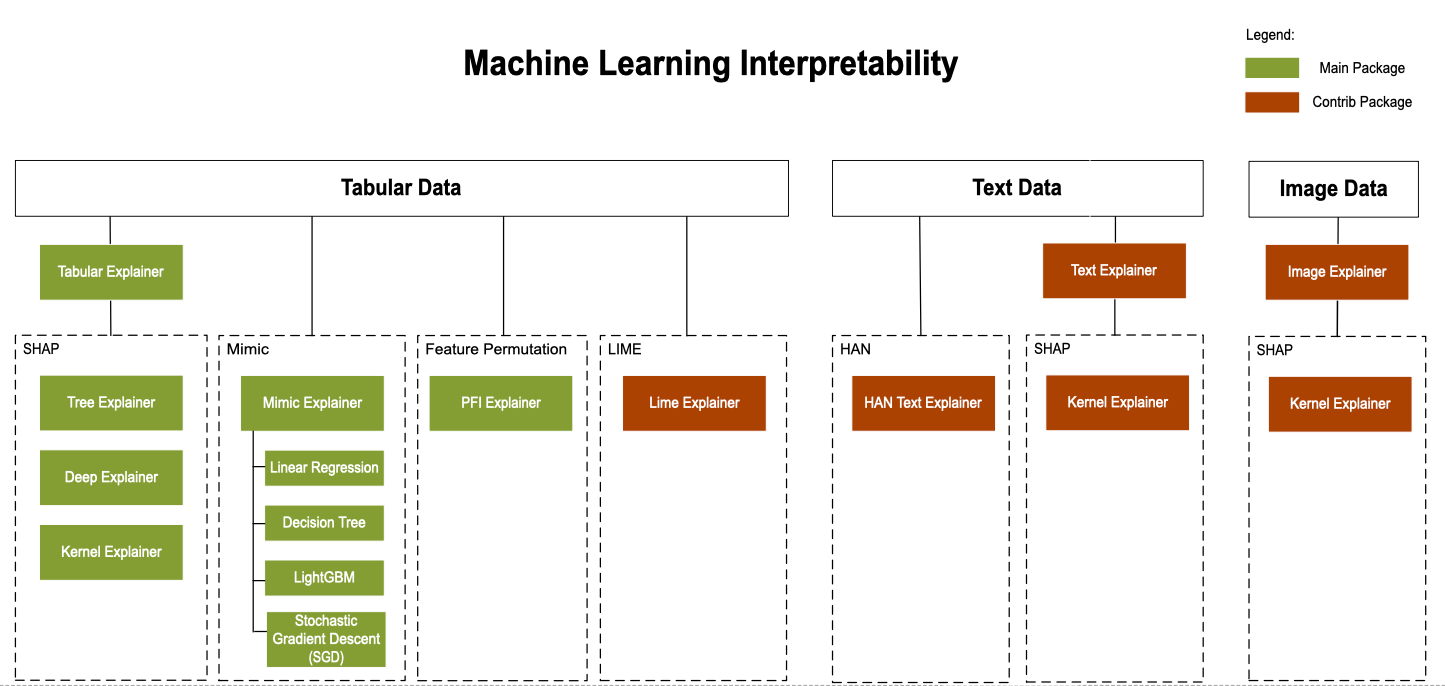
Meta explainers automatically select a suitable direct explainer and generate the best explanation info based on the given model and data sets. The meta explainers leverage all the libraries (SHAP, LIME, Mimic, etc.) that we have integrated or developed. The following are the meta explainers available in the SDK:
- Tabular Explainer: Used with tabular datasets.
- Text Explainer: Used with text datasets.
- Image Explainer: Used with image datasets.
In addition to Meta-selecting of the direct explainers, meta explainers develop additional features on top of the underlying libraries and improve the speed and scalability over the direct explainers.
Currently TabularExplainer employs the following logic to invoke the Direct SHAP Explainers:
- If it’s a tree-based model, apply SHAP
TreeExplainer, else - If it’s a DNN model, apply SHAP
DeepExplainer, else - Treat it as a black-box model and apply SHAP
KernelExplainer
The intelligence built into TabularExplainer will become more sophisticated as more libraries are integrated into the SDK and we learn about pros and cons of each explainer.
TabularExplainer has also made significant feature and performance enhancements over the Direct Explainers:
- Summarization of the initialization dataset. In cases where speed of explanation is most important, we summarize the initialization dataset and generate a small set of representative samples, which speeds up both global and local explanation.
- Sampling the evaluation data set. If the user passes in a large set of evaluation samples but doesn’t actually need all of them to be evaluated, the sampling parameter can be set to true to speed up the global explanation.
The following diagram shows the current structure of direct and meta explainers:
Explain the model (interpretability) within Automated Machine Learning
Automated machine learning allows you to understand feature importance. During the training process, you can get global feature importance for the model. For classification scenarios, you can also get class-level feature importance. You must provide a validation dataset (X_valid) to get feature importance.
There are two ways to generate feature importance.
- Once an experiment is complete, you can use
explain_modelmethod on any iteration:

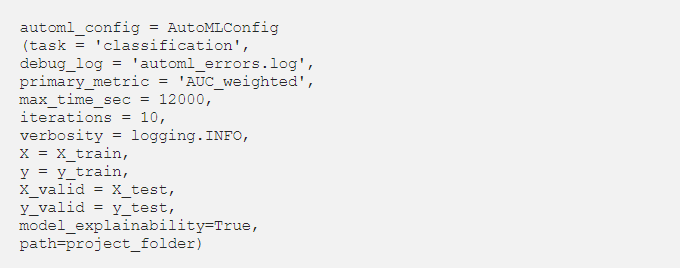
- To view feature importance for all iterations, set
model_explainabilityflag toTruein AutoMLConfig:
Once done, you can use retrieve_model_explanation method to retrieve feature importance for a specific iteration:

You can visualize the feature importance chart in your workspace in the Azure portal:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
