Extract-Transform-Load Framework
General Concerns
The general concerns when we try to import Data from RDBMS to Data Lake:
- Multiple Schema/Tables import
- Save in Avro/Parquet/sequence
- Schedule Import Job
- Source Schema Change
- Incremental Import
Main Concern (or Weakness) of Design
Main Concerns or weaknesses of this Architecture is
- Incremental Data Synchronization widely known as Change Data Capture (CDC)
- We have to depends on the mercy of DB architect. If his created_at, and updated_at column not consistent then we will have CDC issue if source data deleted.
Tools we can use
There are so many tools to perform this particular job. For now, I can think of below tools:
- Apache Sqoop (along with Oozie workflow to handle scheduling)
- Apache Spark SQL
- Apache NiFi
- Debezium (Real Time CDC with Kafka/Confluent)
[Disclaimer: Here, I am using all open Source Tools. But we can use paid version tools like Telend, Qlikview etc.]
Apache Sqoop:
Apache Sqoop is the most popular tool for importing data from RDBMS to Data Lake or HDFS.
Concerns from [1-5] all can be resolve with Sqoop except there is a small issue when we need to do incremental import and source schema change frequently. Sqoop can track Insert and Update operation but can not track Delete Operation.

[One way to solve this issue , we can try for MySQL like DBMS, is parsing MySQL binlog to monitor deleted rows. Then use MySQL binlog + sqoop to extract data incrementally.]
Example:
The CUSTOMER data lake needs to capture changes from the source MySQL database. It’s currently at 5 million records. 1 Million customer records in the source have changed and 4 new customer records were added to the source if the data source has updated_at/created_at column.
Working with Sqoop :
- We’re going to use Sqoop in incremental mode to import only those records that were modified
Run Sqoop with the incremental option to get new changes from the source MySQL database and import this into HDFS as a Parquet file.
sqoop import --connect jdbc:mysql://ip-172-31-2-69.us-west-2.compute.internal:3306/mysql --username root --password password -table customer -m4 --target-dir /landing/staging_customer_update_spark --incremental lastmodified --check-column modified_date --last-value "2016-05-23 00:00:00" --as-parquetfile
- We will store modified records in parquet file
- Using Spark SQL, create new tables: one for extracted data and another for updated original table.
- Using Spark SQL, insert unchanged data merged with modified data using LEFT JOIN
Sqoop for AWS : RDS to EMR/S3/Redshift
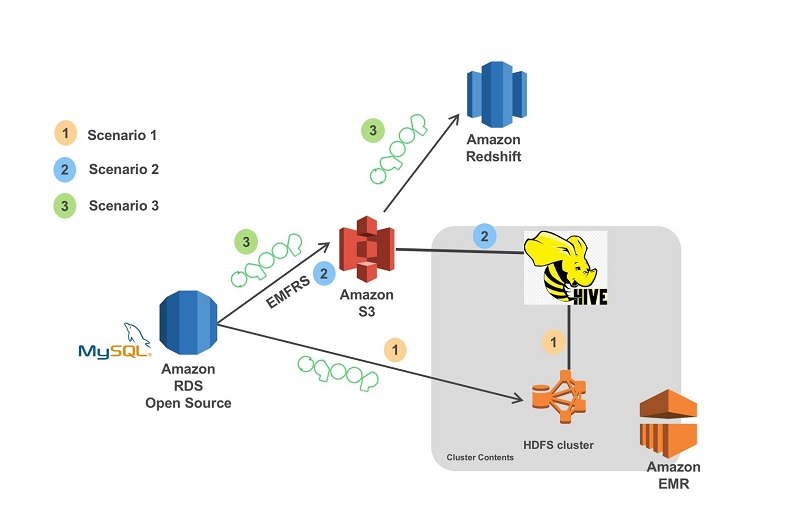
picture courtesy : aws.amazon.com
Apache Spark (PySpark/Scala)
[auto-iframe link=https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/6260061044268019/3041701047393413/635120370383545/latest.html width=1100 height=500 autosize=no]Apache NiFi:
This is the tool for getting the right data to the right place(s), in the right format(s), at the right time.
Working with NiFi:
To import RDBMS, we need to create a DBCPConnectionPool controller service, pointing at our SQL instance, driver, etc. Then we can use any of the following processors to get data from our database:
- ExecuteSQL
- QueryDatabaseTable
- GenerateTableFetch
Once the data is fetched from the database, it is usually in Avro format. If we want it in another format, wewill need to use some conversion processor(s) such as ConvertAvroToJSON.
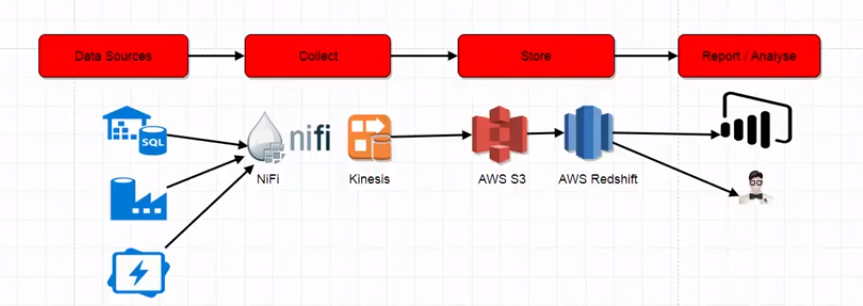
NiFi with Kenesis Firehose to S3 and then to Redshift
Debezium (Real time CDC):
As Debezium is a distributed platform built for CDC, it can use database transaction logs and creates event streams on row-level changes. There are existing Open Source offerings, including: Maxwell, SpinalTap, Yelp’s MySQL Streamer.
Debezium will give us the ability to synchronize RDB (MySQL, Oracle, Postgres) tables with Hive equivalents. Synchronization process should be done by using CDC (change data capture) logs. By using this technique we should get almost real-time synchronization between source and destination table. For the CDC logging purposes, Debezium’s MySQL Connector was used. It can monitor and record all of the row-level changes in the databases on a MySQL server.
Summary
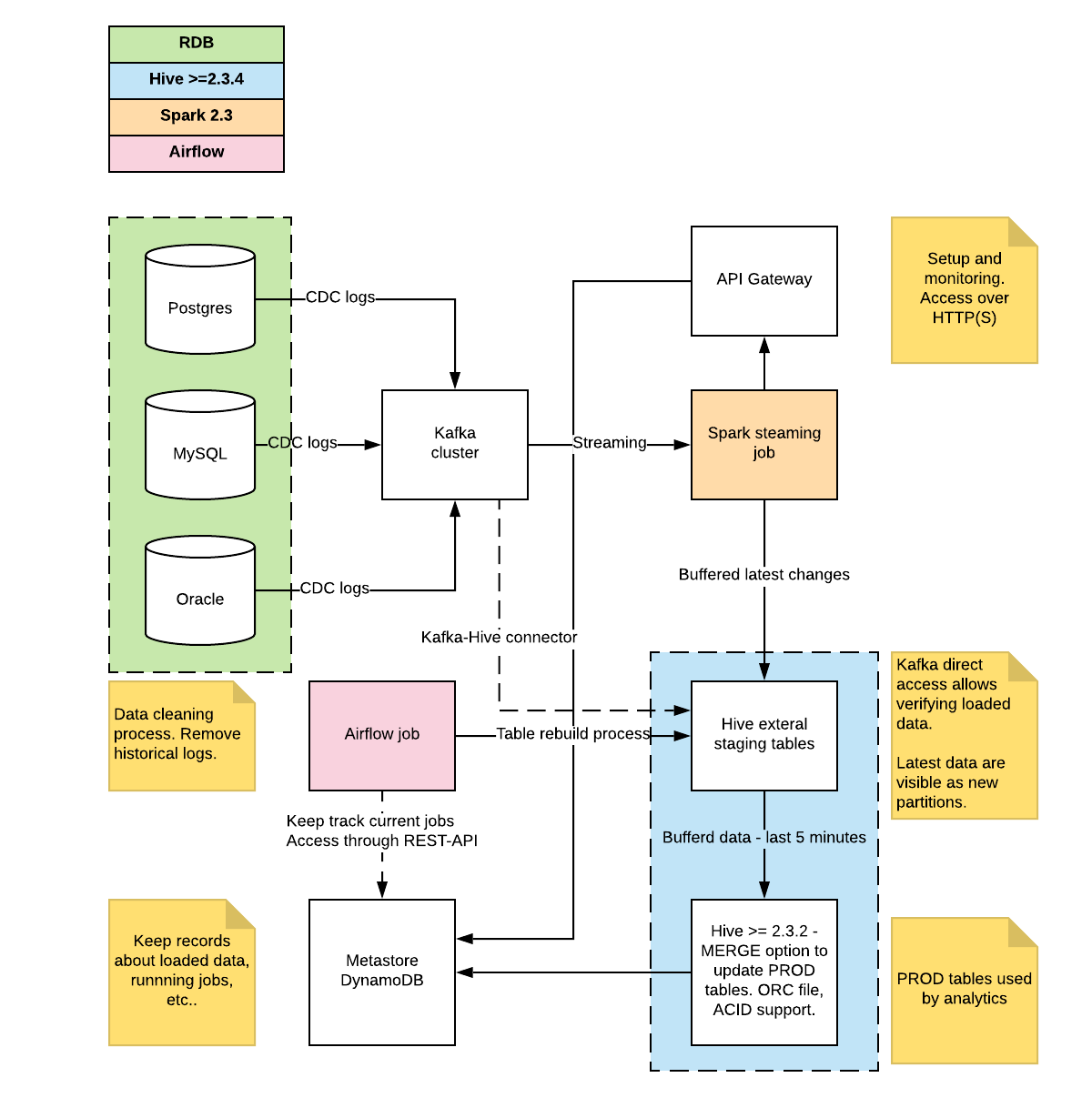
The diagram below shows the architecture concept. So that, if we don’t have any primary key in our schema or if we need to do change data capture in real time then can recommend following workflow. There are three main parts presented below:
- Relational database cluster, configured to generate CDC logs.
- Logs are sent to the Kafka buffer
- Spark streaming job lets to get raw data and push (in a structured way) to the Hive staging table
- Merge process is done in Hive(or any Data lake). To make it work we need to use transaction support in hive.
SQL
[auto-iframe link=http://sqlfiddle.com/#!9/2eeb2e/10 width=1100 height=500 autosize=no]
Basic Programming
https://gist.github.com/arifmarias/030610613294a7b58df442e2de08c4aa
Data Modeling
https://gist.github.com/arifmarias/ac85c27d67f4dc79f54c028707b9c242
3NF E-R Diagram
[auto-iframe link=https://dbdiagram.io/d/5e94012c39d18f5553fd7ee9 width=1100 height=500 autosize=no]
Data Transformation
https://gist.github.com/arifmarias/e541463d22fb1935ab761d22fda681d2