Presentation Files
Related Materials:
- Data Concept
- To know more about Data Concept you can click [this] link.
- ML Performance Metrics:
Prerequisite
Primary Requirements
- Some programming experience
- At least high school level math skills will be required.
- Passion to learn
IDE Requirements
- Most popular IDE for Data Science is Anaconda. You can download and install from here. Make sure your download Python 3.7 distribution.
I don’t have the admin permission to install any software (Don’t worry !)
- Google Colab [if you already have Google Account ]
- Azure Notebook [if you already have Microsoft Account]
- Both are Free ! to use
Is there anyway I can do Machine Learning Analytics with Less Code or No Code?
Yes ! We can.
How?
Step 1 : Please go to this site https://studio.azureml.net/
Step 2 : Use any Microsoft Account(youremail@hotmail.com / outlook.com) to Register and Login
Cheat Sheet
Azure ML Cheat Sheet
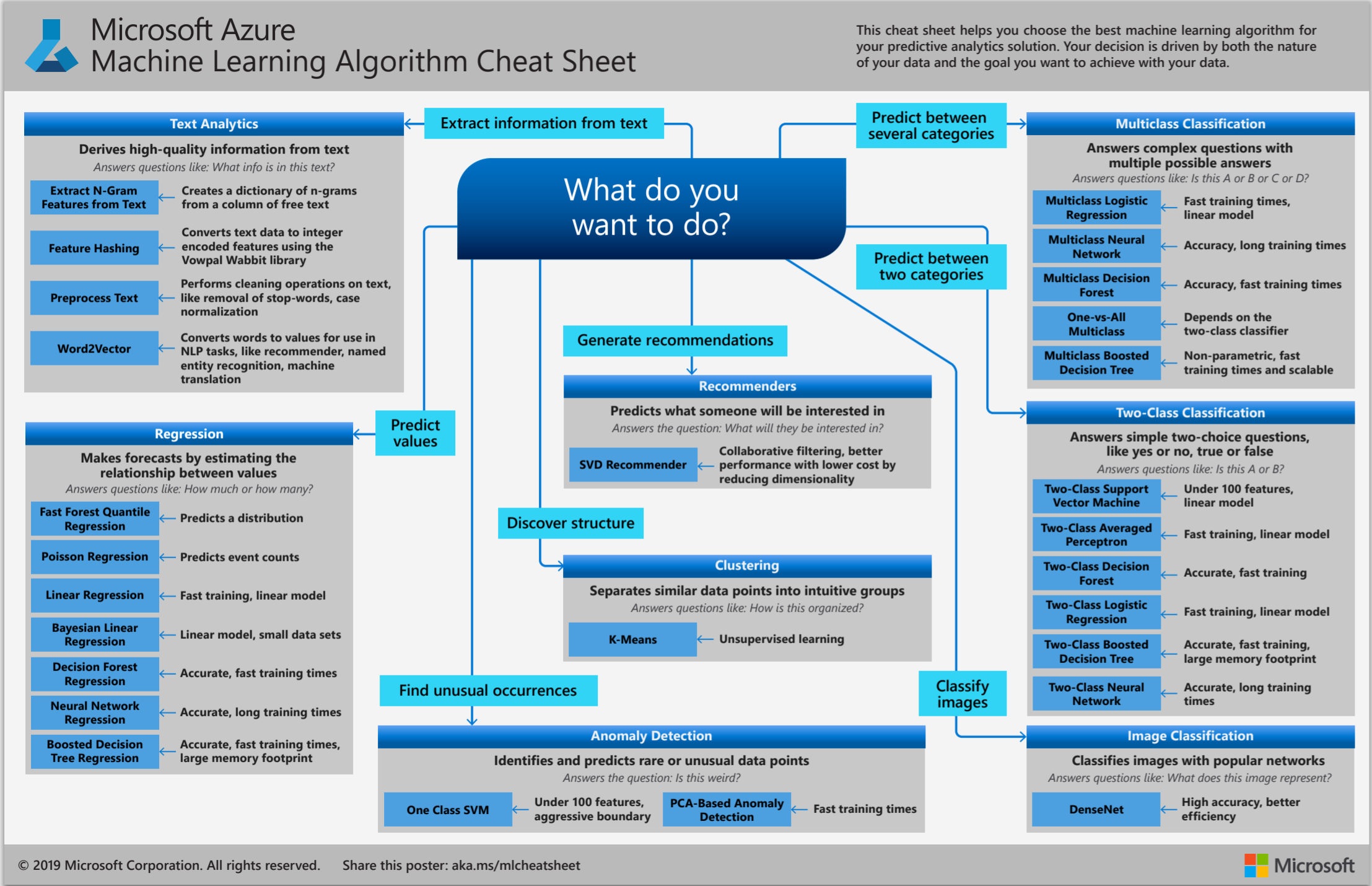
Algorithm Summary
Source: http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/






Hands-on
Predicting Used Car Prices
The Problem
The prices of new cars in the industry is fixed by the manufacturer with some additional costs incurred by the Government in the form of taxes. So, customers buying a new car can be assured of the money they invest to be worthy. But due to the increased price of new cars and the incapability of customers to buy new cars due to the lack of funds, used cars sales are on a global increase (Pal, Arora and Palakurthy, 2018). There is a need for a used car price prediction system to effectively determine the worthiness of the car using a variety of features. Even though there are websites that offers this service, their prediction method may not be the best. Besides, different models and systems may contribute on predicting power for a used car’s actual market value. It is important to know their actual market value while both buying and selling.
The Client
To be able to predict used cars market value can help both buyers and sellers.
Used car sellers (dealers): They are one of the biggest target group that can be interested in results of this study. If used car sellers better understand what makes a car desirable, what the important features are for a used car, then they may consider this knowledge and offer a better service.
Online pricing services: There are websites that offers an estimate value of a car. They may have a good prediction model. However, having a second model may help them to give a better prediction to their users. Therefore, the model developed in this study may help online web services that tells a used car’s market value.
Individuals: There are lots of individuals who are interested in the used car market at some points in their life because they wanted to sell their car or buy a used car. In this process, it’s a big corner to pay too much or sell less then it’s market value.
The Data
The data used in this project was downloaded from Kaggle. It was uploaded on Kaggle by Austin Reese who Kaggle.com user. Austin Reese scraped this data from craigslist with non-profit purpose. It contains most all relevant information that Craigslist provides on car sales including columns like price, condition, manufacturer, latitude/longitude, and 22 other categories.
Dataset Collected from here : https://www.kaggle.com/austinreese/craigslist-carstrucks-data
Solution
There are two ways we can do this; either we can solve this with Azure ML Designer (No Code) way or We can do this using python notebook.
- Let’s do this using Azure ML Designer (Azure ML Studio -Classic)
- If you’re Python savvy you can follow [this] link for get your ipynb files.
Practice
Heart Diseases Prediction
The Problem
The term “heart disease” is often used interchangeably with the term “cardiovascular disease”. Cardiovascular disease generally refers to conditions that involve narrowed or blocked blood vessels that can lead to a heart attack, chest pain (angina) or stroke. Other heart conditions, such as those that affect your heart’s muscle, valves or rhythm, also are considered forms of heart disease.
This makes heart disease a major concern to be dealt with. But it is difficult to identify heart disease because of several contributory risk factors such as diabetes, high blood pressure, high cholesterol, abnormal pulse rate, and many other factors. Due to such constraints, scientists have turned towards modern approaches like Data Science and Machine Learning for predicting the disease.
The Data
In this practicec, we will be applying Machine Learning approaches (and eventually comparing them) for classifying whether a person is suffering from heart disease or not, using one of the most used dataset — Cleveland Heart Disease dataset from the UCI Repository.
Data Source URL : http://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data
Solution
There are two ways we can do this; either we can solve this with Azure ML Designer (No Code) way or We can do this using python notebook.
- Let’s do this using Azure ML Designer (Azure ML Studio -Classic)
- If you’re Python savvy you can follow [this] link for get your ipynb files and to read the blog about this problem scope you can visit this [link]
Hints:
- Edit Metadata info and put new column name : age,sex,chestpaintype,resting_blood_pressure,serum_cholestrol,fasting_blood_sugar,resting_ecg,max_heart_rate,exercise_induced_angina,st_depression_induced_by_exercise,slope_of_peak_exercise,number_of_major_vessel,thal,heart_disease_diag
- Edit Metadata info and Change Data type to Integer for following Columns: heart_disease_diag,age,sex
- Edit Metadata info and make it categorical for following Columns: sex,chestpaintype,exercise_induced_angina,number_of_major_vessel,slope_of_peak_exercise,fasting_blood_sugar,thal,resting_ecg
- Clean Missing Value
- Apply SQL Transformation
SELECT *,
CASE
WHEN heart_disease_diag < 1 THEN 0
ELSE 1
END AS HeartDiseaseCat
FROM t1;
Course Outline
Module 1: Introduction to Azure Machine Learning
In this module, you will learn how to provision an Azure Machine Learning workspace and use it to manage machine learning assets such as data, compute, model training code, logged metrics, and trained models. You will learn how to use the web-based Azure Machine Learning studio interface as well as the Azure Machine Learning SDK and developer tools like Visual Studio Code and Jupyter Notebooks to work with the assets in your workspace.
Lessons
- Getting Started with Azure Machine Learning
- Azure Machine Learning Tools
Lab : Creating an Azure Machine Learning Workspace
Lab : Working with Azure Machine Learning Tools
After completing this module, you will be able to
- Provision an Azure Machine Learning workspace
- Use tools and code to work with Azure Machine Learning
Module 2: Visual Tools for Machine Learning
This module introduces the Designer tool, a drag and drop interface for creating machine learning models without writing any code. You will learn how to create a training pipeline that encapsulates data preparation and model training, and then convert that training pipeline to an inference pipeline that can be used to predict values from new data, before finally deploying the inference pipeline as a service for client applications to consume.
Lessons
- Training Models with Designer
- Publishing Models with Designer
Lab : Creating a Training Pipeline with the Azure ML Designer
Lab : Deploying a Service with the Azure ML Designer
After completing this module, you will be able to
- Use designer to train a machine learning model
- Deploy a Designer pipeline as a service
Module 3: Running Experiments and Training Models
In this module, you will get started with experiments that encapsulate data processing and model training code, and use them to train machine learning models.
Lessons
- Introduction to Experiments
- Training and Registering Models
Lab : Running Experiments
Lab : Training and Registering Models
After completing this module, you will be able to
- Run code-based experiments in an Azure Machine Learning workspace
- Train and register machine learning models
Module 4: Working with Data
Data is a fundamental element in any machine learning workload, so in this module, you will learn how to create and manage datastores and datasets in an Azure Machine Learning workspace, and how to use them in model training experiments.
Lessons
- Working with Datastores
- Working with Datasets
Lab : Working with Datastores
Lab : Working with Datasets
After completing this module, you will be able to
- Create and consume datastores
- Create and consume datasets
Module 5: Working with Compute
One of the key benefits of the cloud is the ability to leverage compute resources on demand, and use them to scale machine learning processes to an extent that would be infeasible on your own hardware. In this module, you’ll learn how to manage experiment environments that ensure consistent runtime consistency for experiments, and how to create and use compute targets for experiment runs.
Lessons
- Working with Environments
- Working with Compute Targets
Lab : Working with Environments
Lab : Working with Compute Targets
After completing this module, you will be able to
- Create and use environments
- Create and use compute targets
Module 6: Orchestrating Operations with Pipelines
Now that you understand the basics of running workloads as experiments that leverage data assets and compute resources, it’s time to learn how to orchestrate these workloads as pipelines of connected steps. Pipelines are key to implementing an effective Machine Learning Operationalization (ML Ops) solution in Azure, so you’ll explore how to define and run them in this module.
Lessons
- Introduction to Pipelines
- Publishing and Running Pipelines
Lab : Creating a Pipeline
Lab : Publishing a Pipeline
After completing this module, you will be able to
- Create pipelines to automate machine learning workflows
- Publish and run pipeline services
Module 7: Deploying and Consuming Models
Models are designed to help decision making through predictions, so they’re only useful when deployed and available for an application to consume. In this module learn how to deploy models for real-time inferencing, and for batch inferencing.
Lessons
- Real-time Inferencing
- Batch Inferencing
Lab : Creating a Real-time Inferencing Service
Lab : Creating a Batch Inferencing Service
After completing this module, you will be able to
- Publish a model as a real-time inference service
- Publish a model as a batch inference service
Module 8: Training Optimal Models
By this stage of the course, you’ve learned the end-to-end process for training, deploying, and consuming machine learning models; but how do you ensure your model produces the best predictive outputs for your data? In this module, you’ll explore how you can use hyperparameter tuning and automated machine learning to take advantage of cloud-scale compute and find the best model for your data.
Lessons
- Hyperparameter Tuning
- Automated Machine Learning
Lab : Tuning Hyperparameters
Lab : Using Automated Machine Learning
After completing this module, you will be able to
- Optimize hyperparameters for model training
- Use automated machine learning to find the optimal model for your data
Module 9: Responsible Machine Learning
Many of the decisions made by organizations and automated systems today are based on predictions made by machine learning models. It’s increasingly important to be able to understand the factors that influence the predictions made by a model, and to be able to determine any unintended biases in the model’s behavior. This module describes how you can interpret models to explain how feature importance determines their predictions.
Lessons
- Introduction to Model Interpretation
- using Model Explainers
Lab : Reviewing Automated Machine Learning Explanations
Lab : Interpreting Models
After completing this module, you will be able to
- Generate model explanations with automated machine learning
- Use explainers to interpret machine learning models
Module 10: Monitoring Models
After a model has been deployed, it’s important to understand how the model is being used in production, and to detect any degradation in its effectiveness due to data drift. This module describes techniques for monitoring models and their data.
Lessons
- Monitoring Models with Application Insights
- Monitoring Data Drift
Lab : Monitoring a Model with Application Insights
Lab : Monitoring Data Drift
After completing this module, you will be able to
- Use Application Insights to monitor a published model
- Monitor data drift
Azure ML Learning Path
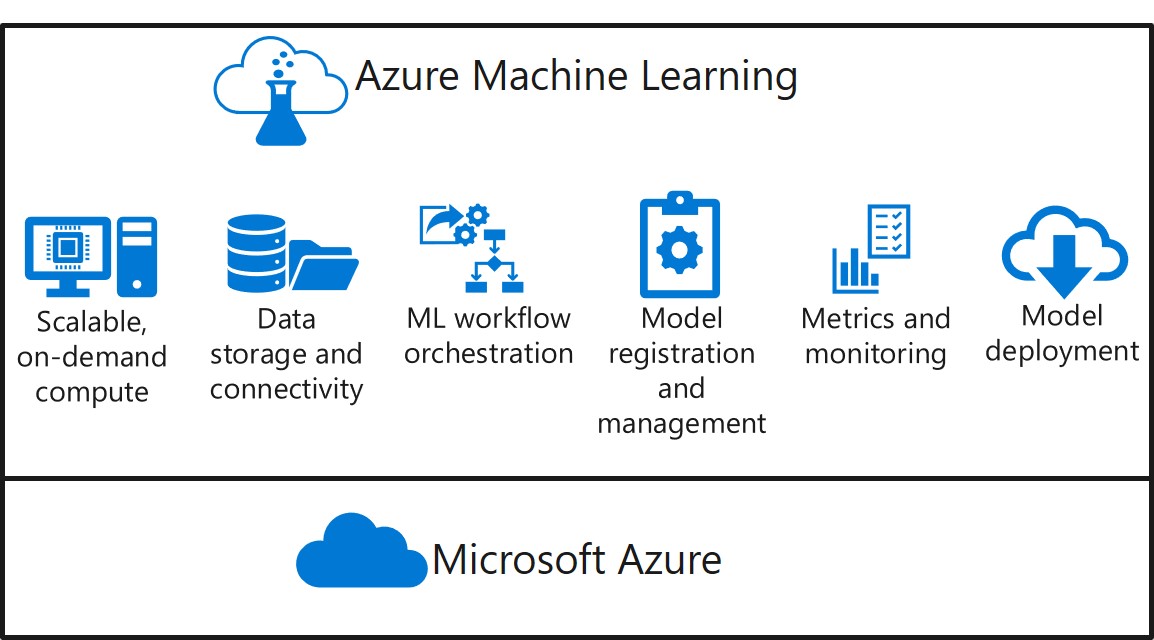
Azure Machine Learning
A set of services for training, testing and deploying your own Machine Learning models.
Machine Learning Services
What is it?
- Simplify and accelerate the building, training, and deployment of your machine learning models. Use automated machine learning to identify suitable algorithms and tune hyperparameters faster. Improve productivity and reduce costs with autoscaling compute and DevOps for machine learning. Seamlessly deploy to the cloud and the edge with one click. Access all these capabilities from your favorite Python environment using the latest open-source frameworks, such as PyTorch, TensorFlow, and scikit-learn.
Who is it for?
- Data Scientists, Machine Learning experts (code-first, Python-focused)
Learning Resources
- 📃 Landing page
- 📺 AI with Azure Machine Learning services: Simplifying the data science process – BRK2304
- 💡 Bootcamp Materials
Machine Learning Studio
What is it?
- A fully-managed cloud service that enables you to easily build, deploy, and share predictive analytics solutions. Machine Learning Studio is a powerfully simple browser-based, visual drag-and-drop authoring environment where no coding is necessary. Go from idea to deployment in a matter of clicks.
Who is it for?
- Data Scientists, Machine Learning experts, Developers (Low/No-Code)
Learning Resources
- 📃 Landing page
- 📺 Azure Machine Learning Demo |70-774 Perform Cloud Data Science with Azure Machine Learning Tutorial
Azure Databricks
What is it?
- Accelerate big data analytics and artificial intelligence (AI) solutions with Azure Databricks, a fast, easy and collaborative Apache Spark–based analytics service.
- Set up your Spark environment in minutes and autoscale quickly and easily. Data scientists, data engineers, and business analysts can collaborate on shared projects in an interactive workspace. Apply your existing skills with support for Python, Scala, R, and SQL, as well as deep learning frameworks and libraries like TensorFlow, Pytorch, and Scikit-learn. Native integration with Azure Active Directory (Azure AD) and other Azure services enables you to build your modern data warehouse and machine learning and real-time analytics solutions.
Who is it for?
- Apache Spark users, Data Scientists, Machine Learning experts
Learning Resources
- 📃 Landing Page
- 📃 Quickstart Guide
- 📺 Microsoft Azure Databricks – Azure Power Lunch
- 📺 Real-time analytics with Azure Databricks and Azure Event Hubs – BRK3203
Taxonomy
A taxonomy of the workspace is illustrated in the following diagram:

Presentation Files
- DP-100T01A-ENU-PowerPoint_00
- DP-100T01A-ENU-PowerPoint_01
- DP-100T01A-ENU-PowerPoint_02
- DP-100T01A-ENU-PowerPoint_03
- DP-100T01A-ENU-PowerPoint_04
- DP-100T01A-ENU-PowerPoint_05
- DP-100T01A-ENU-PowerPoint_06
- DP-100T01A-ENU-PowerPoint_07
- DP-100T01A-ENU-PowerPoint_08
- DP-100T01A-ENU-PowerPoint_09
- DP-100T01A-ENU-PowerPoint_10
Lab Files
You can find all Lab Files and Instructions here.
Github link for labfiles : https://github.com/MicrosoftLearning/mslearn-dp100
| Exercises |
|---|
Important: Remember to stop any virtual machines used in these labs when you no longer need them – this will minimize the Azure credit incurred for these services. When you have completed all of the labs, consider deleting the resource group you created if you don’t plan to experiment with it any further.
Extra Resources
Dataset
Mindmap
- Click here
Checklist
Book
Documentation
AML Cheat Sheet
Data Concept
- To know more about Data Concept you can click [this] link.
ML Performance Metrics:
Hyperparameter Tuning
- Solving different Optimization Problem
Interpretable Machine Learning
- Interpreting Models
- You can use this notebook file where you can use your local model to explanation.
- For more clarity this video can help you.
Azure Machine Learning Notebooks
- Different Notebooks are available for Different Services
Summary
- Summary – Azure Machine Learning Service
- There is a web series from Facundo Santiago [Part 1], [Part 2] and [Part 3]
Knowledge Check
- Please Open this link
- Copy and Paste the Room Name: DP100
- Click to Join
- Enter your Name
Question Bank (For Practice Only)
https://free-braindumps.com/microsoft/free-dp-100-braindumps.html?p=2
Disclaimer:
Some of the Solution might not correct. Please verify with Microsoft Knowledge/Documentation.
Please be consider that above link for dummy questions is a third party site and I don’t have any acquaintances with them.
Hands-On (For Practice Only)
Please follow the below github link for the Lab Instructions and Data:
https://github.com/arifmarias/DP100Practice
- Go to Practice Lab Folder for Lab Instructions
- Check the Data folder for Lab Dataset
- Enter the following command to clone a Git repository containing notebooks, data, and other files to your workspace:
git clone https://github.com/arifmarias/DP100Practice